5 Controlando confundidores (critério backdoor)
Um confundidor é uma causa comum, direta ou indireta, de em . Na existência de confundidores, a regressão de em no modelo observacional, , é diferente desta regressão no modelo de intervenção, . Isto ocorre pois, quando calculamos , utilizamos toda a informação em para prever . Esta informação inclui não apenas o efeito causal de em , como também a informação que traz indiretamente sobre pelo fato de ambas estarem associados aos seus confundidores.
Para ilustrar este raciocínio, podemos revisitar o Exemplo 3.5. uma vez que Sexo (Z) é causa comum do Tratamento (X) e da Cura (Y), Z é um confundidor. Quando calculamos (Seção 4), utilizamos não só o efeito direto de em , expresso em , como também a informação que indireta que traz sobre por meio do confundidor , expressa pela combinação de com .
Esta seção desenvolve uma estratégia para medir o efeito causal chamada de critério backdoor, que consiste em bloquear todos os caminhos de informação que passam por confundidores:
Definição 3.11.
Seja um grafo causal e . Dizemos que satisfaz o critério “backdoor” se:
-
1.
,
-
2.
Para todo caminho de em , tal que , está bloqueado dado .
Exemplo 3.12.
No Exemplo 3.5 o único caminho de em em que o vértice ligado a é pai de é . Como é um confudidor neste caminho, ele o bloqueia. Assim, satisfaz o critério backdoor.
Exemplo 3.13.
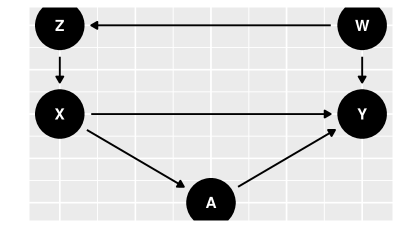
Considere o grafo causal na figur 10. Para aplicar o critério backdoor, devemos identificar todos os caminhos de em em que o vértice ligado a é pai de , isto é, temos . O único caminho deste tipo é: . Neste caminho, é uma cadeia e é um confudidor. Assim, é possível bloquear este caminho condicionando em , em , e em . Isto é, todos estas combinações satisfazem o critério backdoor.
Exemplo 3.14.
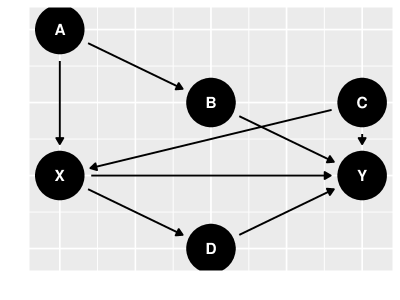
Considere o grafo causal na figur 11. Para aplicar o critério backdoor, encontramos todos os caminhos de em em que o vértice ligado a é pai de . Há dois caminhos deste tipo: e . Como e são confudidores, respectivamente, no primeiro e segundo caminhos, bloqueia ambos eles. Assim satisfaz o critério backdoor. Você consegue encontrar outro conjunto de variáveis que satisfaz o critério backdoor?
Também é possível identificar os conjuntos de variáveis que satisfazem o critério backdoor por meio do pacote dagitty, como ilustrado a seguir:
library(dagitty) # Especificar o grafo grafo <- dagitty("dag{ X[e] Y[o] A -> { X B }; B -> { Y }; C -> { X Y }; X -> { D Y }; D -> Y }") adjustmentSets(grafo, type = "all")
## { A, C }
## { B, C }
## { A, B, C }
O critério backdoor generaliza duas condições especiais que são muito utilizadas. Em uma primeira condição, o valor de é gerado integralmente por um aleatorizador, independente de todas as demais variáveis. Esta ideia é captada pela Definição 3.15, abaixo:
Definição 3.15.
Dizemos que é um experimento aleatorizado simples se é ancestral.
Em um experimento aleatorizado simples não há confundidores. Assim, satisfaz o critério backdoor:
Lema 3.16.
Se é um experimento aleatorizado simples, então satisfaz o critério backdoor.
Veremos que em um experimento aleatorizado simples a distribuição intervencional é igual à distribuição observacional. Assim, e a inferência causal é reduzida à inferência comumente usadas para a distribuição observacional.
Além disso, o conjunto de todos os pais de também satisfaz o critério backdoor:
Lema 3.17.
satisfaz o critério backdoor para medir o efeito causal de em .
A seguir, veremos como o critério backdoor permite a identificação causal, isto é, uma equivalência entre quantidades de interesse obtidas pelo modelo de intervenção e quantidades obtidas pelo modelo observacional.
5.1 Identificação causal usando o critério backdoor
A seguir, o Teorema 3.19 mostra que, se satisfaz o critério backdoor, então é possível ligar algumas distribuições sob intervenção em a distribuições observacionais:
Definição 3.18.
controla confundidores para medir o efeito causal de em se
Teorema 3.19.
Se satisfaz o critério backdoor para medir o efeito causal de em , então satisfaz a Definição 3.18.
O Teorema 3.19 mostra que, se satisfaz o critério backdoor, então distribuição de quando aplicamos uma intervenção em é igual à distribuição marginal de . Além disso, a distribuição condicional de dado quando aplicamos uma intervenção em é igual à distribuição de dado e . Assim, o Teorema 3.19 relaciona distribuições que não geraram os dados a distribuições que os geraram. Com base neste resultado, é possível determinar a partir de :
Corolário 3.20.
Se satisfaz a Definição 3.18, então
Para compreender intuitivamente o Corolário 3.20, podemos retornar ao Exemplo 3.5. Considere o caso em que são as indicadoras de que, respectivamente, o paciente foi submetido ao tratamento, se curou e, é de sexo masculino. Similarmente ao Teorema 3.19, vimos em Exemplo 3.5 que é a média de ponderada por . Nesta ponderação, utilizamos ao invés de pois é um confundidor e, assim, no modelo intervencional não propagamos a informação em por esta variável. A mesma lógica se aplica às variáveis que satisfazem o critério backdoor.
Para calcular quantidades como o (Definição 3.4), utilizamos . Por meio do Teorema 3.19, é possível obter equivalências entre e esperanças obtidas no modelo observacional. Estas equivalências são descritas nos Teoremas 3.21 e 3.22.
Teorema 3.21.
Se satisfaz a Definição 3.18, então
Teorema 3.22.
Se satisfaz a Definição 3.18 e é discreto, então
A seguir, veremos como os Teoremas 3.21 e 3.22 podem ser usados para estimar o efeito causal. Para provar resultados sobre os estimadores obtidos, a seguinte definição será útil
Definição 3.23.
Seja um estimador treinado com os dados . Dizemos que é invariante a permutações se o estimador não depende da ordem dos dados. Isto é, para qualquer permutações dos índices, ,
Exemplo 3.24.
A média amostral é invariante a permutações pois, para qualquer permutação ,
5.2 Estimação usando o critério backdoor
5.2.1 Fórmula do ajuste
Se satisfaz a Definição 3.18, então . Como é a função de regressão de em e , podemos estimar utilizando quaisquer métodos de estimação para regressão. Por exemplo, se é contínua, possíveis métodos são: regressão linear, Nadaraya-Watson, floresta aleatória de regressão, redes neurais, …Por outro lado, se é discreta, então a função de regressão é estimada por métodos de classificação como: regressão logística, k-NN, floresta aleatória de classificação, redes neurais, …Para qualquer opção escolhida, denotamos o estimador de por .
Utilizando , podemos estimar diretamente. Para tal, note que é função de . Como o Teorema 3.21 garante que , podemos definir o estimador
O Teorema 3.21 também orienta a estimação do . Similarmente ao caso anterior, o é função de . Pelo Teorema 3.21, . Assim, se , . Como é simplesmente uma média populacional, podemos estimá-la com base na média amostral:
Definição 3.25.
Considere que satisfaz a Definição 3.18 e é uma estimativa da regressão . Os estimadores de e pela fórmula do ajuste são:
A seguir mostraremos que, se converge para , então converge para . Em outras palavras, é possível utilizar para estimar o efeito causal de em por meio de expressões como o .
Teorema 3.26.
Seja . Se satisfaz a Definição 3.18, , , e é invariante a permutações (Definição 3.23), então .
A seguir, utilizamos dados simulados para ilustrar a implementação da fórmula do ajuste.
Exemplo 3.27.
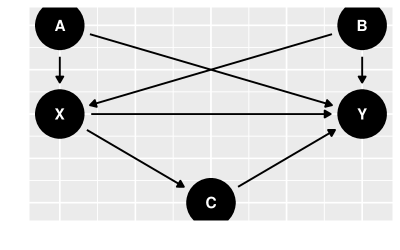
Considere que o grafo causal é dado pela figur 12. Vamos supor que os dados são gerados da seguinte forma: , , , , , e :
# Especificar o grafo grafo <- dagitty::dagitty("dag { X[e] Y[o] {A B} -> { X Y }; X -> {C Y}; C -> Y }") # Simular os dados n <- 10^5 sd = 0.1 A <- rnorm(n, 0, sd) B <- rnorm(n, 0, sd) eps <- rbinom(n, 1, 0.8) X <- as.numeric(eps*((A + B) > 0) + (1-eps)*((A + B) <= 0)) C <- rnorm(n, X, sd) Y <- rnorm(n, A + B + C + X, sd) data <- dplyr::tibble(A, B, C, X, Y)
Estimaremos o efeito causal pela fórmula do ajuste (Definição 3.25). Iniciaremos a análise utilizando como sendo uma regressão linear simples:
# Sejam Z variáveis que satisfazem o critério backdoor para # estimar o efeito causal de causa em efeito em grafo. # Retorna uma fórmula do tipo Y ~ X + Z˙1 + … + Z˙d fm_ajuste <- function(grafo, causa, efeito) { var_backdoor <- dagitty::adjustmentSets(grafo)[[1]] regressores = c(causa, var_backdoor) fm = paste(regressores, collapse = "+") fm = paste(c(efeito, fm), collapse = "~") as.formula(fm) } # Estima E[Efeito—do(causa = x)] pela # formula do ajuste usando mu˙chapeu como regressao est_do_x_lm <- function(data, mu_chapeu, causa, x) { data %>% dplyr::mutate({{causa}} := x) %>% predict(mu_chapeu, newdata = .) %>% mean() } # Estimação do ACE com regressão linear simples fm <- fm˙ajuste(grafo, "X", "Y") mu_chapeu_lm <- lm(fm, data = data) ace_ajuste_lm = est˙do˙x˙lm(data, mu_chapeu_lm, "X", 1) - est˙do˙x˙lm(data, mu_chapeu_lm, "X", 0) round(ace_ajuste_lm)
## [1] 2
Em alguns casos, não é razoável supor que é linear. Nestas situações, é fácil adaptar o código anterior para algum método não-paramétrico arbitrário. Exibimos uma implementação usando XGBoost (Chen2023):
library(xgboost) var_backdoor <- dagitty::adjustmentSets(grafo, "X", "Y")[[1]] mu_chapeu <- xgboost( data = data %>% dplyr::select(all˙of(c(var_backdoor, "X"))) %>% as.matrix(), label = data %>% dplyr::select(Y) %>% as.matrix(), nrounds = 100, objective = "reg:squarederror", early_stopping_rounds = 3, max_depth = 2, eta = .25, verbose = FALSE ) est_do_x_xgb <- function(data, mu_chapeu, causa, x) { data %>% dplyr::mutate({{causa}} := x) %>% dplyr::select(c(var_backdoor, causa)) %>% as.matrix() %>% predict(mu_chapeu, newdata = .) %>% mean() } ace_est_xgb = est˙do˙x˙xgb(data, mu_chapeu, "X", 1) - est˙do˙x˙xgb(data, mu_chapeu, "X", 0) round(ace_est_xgb, 2)
## [1] 2
Como o modelo linear era adequado para , não vemos diferença entre a estimativa obtida pela regressão linear simples e pelo XGBoost. Mas será que as estimativas estão adequadas? Como simulamos os dados, é possível calcular diretamente :
| Lei da esperança total | |||||
| (6) | |||||
Uma vez calculado , podemos obter o :
Portanto, as estimativas do obtidas pela regressão linear e pelo xgboost estão adequadas.
5.2.2 Ponderação pelo inverso do escore de propensidade (IPW)
Uma outra forma de estimar e é motivada pelo Teorema 3.22. Este resultado determina que, se satisfaz a Definição 3.18, então
Na segunda expressão, é a regressão de em . Assim, esta quantidade pode ser estimada por um método de regressão arbitrário, que denotaremos por . Também é usualmente chamado de escore de propensidade. Este escore captura a forma como os confundidores atuam sobre nos dados observacionais. Como em geral é desconhecido, também o é. Contudo, quando é discreto, podemos estimar utilizando algum algoritmo arbitrário de classificação. Denotaremos esta estimativa por . Se a estimativa for boa, temos
O Teorema 3.22 também orienta a estimação de . Se satisfaz o critério backdoor, então
Como nesta expressão a esperança é uma média populacional, ela pode ser aproximada pela média amostral
Combinando estas aproximações, obtemos:
Definição 3.28.
Considere que satisfaz a Definição 3.18 e é uma estimativa de . Os estimadores de e por IPW são:
Se converge para , então sob condições relativamente pouco restritivas converge para .
Teorema 3.29.
Se satisfaz a Definição 3.18, também é invariante a permutações (Definição 3.23), , e existe tal que , e existe tal que , então .
A seguir, utilizamos novamente dados simulados para ilustrar a implementação de IPW:
Exemplo 3.30.
Considere que o grafo causal e o modelo de geração dos dados são idênticos àqueles do Exemplo 3.27. Iniciaremos a análise utilizando regressão logística para estimar .
# Sejam Z variáveis que satisfazem o critério backdoor para # estimar o efeito causal de causa em efeito em grafo. # Retorna uma fórmula do tipo X ~ Z˙1 + … + Z˙d fm_ipw <- function(grafo, causa, efeito) { var_backdoor <- dagitty::adjustmentSets(grafo)[[1]] fm = paste(var_backdoor, collapse = "+") fm = paste(c(causa, fm), collapse = "~") as.formula(fm) } # Estimação do ACE por IPW onde # Supomos X binário e # f˙1 é o vetor P(X˙i=1—Z˙i) ACE_ipw <- function(data, causa, efeito, f_1) { data %>% mutate(f_1 = f_1, est_1 = {{efeito}}*({{causa}}==1)/f_1, est_0 = {{efeito}}*({{causa}}==0)/(1-f_1) ) %>% summarise(do_1 = mean(est_1), do_0 = mean(est_0)) %>% mutate(ACE = do_1 - do_0) %>% dplyr::select(ACE) } fm <- fm˙ipw(grafo, "X", "Y") f_chapeu <- glm(fm, family = "binomial", data = data) f_1_lm <- predict(f_chapeu, type = "response") ace_ipw_lm <- data %>% ACE˙ipw(X, Y, f_1_lm) %>% as.numeric() ace_ipw_lm %>% round(2)
## [1] 2.09
Também é fácil adaptar o código acima para estimar por IPW utilizando algum método não-paramétrico para estimar . Abaixo há um exemplo utilizando o XGBoost:
var_backdoor <- dagitty::adjustmentSets(grafo)[[1]] f_chapeu <- xgboost( data = data %>% dplyr::select(all˙of(var_backdoor)) %>% as.matrix(), label = data %>% dplyr::select(X) %>% as.matrix(), nrounds = 100, objective = "binary:logistic", early_stopping_rounds = 3, max_depth = 2, eta = .25, verbose = FALSE ) covs <- data %>% dplyr::select(all˙of(var_backdoor)) %>% as.matrix() f_1 <- predict(f_chapeu, newdata = covs) data %>% ACE˙ipw(X, Y, f_1) %>% as.numeric() %>% round(2)
## [1] 1.97
5.2.3 Estimador duplamente robusto
Os Teoremas 3.26 e 3.29 mostram que, sob suposições diferentes, e convergem para . A ideia do estimador duplamente robusto é combinar ambos os estimadores de forma a garantir esta convergência sob suposições mais fracas. Para tal, a ideia por trás do estimador duplamente é que este convirja junto a quando este é consistente e para quando aquele o é.
Definição 3.31.
Se satisfaz a Definição 3.18 e sejam e tais quais nas Definições 3.25 e 3.28. O estimador duplamente robusto para , é tal que
O estimador duplamente robusto é consistente para tanto sob as condições do Teorema 3.26 quanto sob as do Teorema 3.29. A ideia básica é que, sob as condições do Teorema 3.26, é consistente para e converge para . Isto é, quando é consistente, o estimador duplamente robusto seleciona este termo. Similarmente, sob as condições do Teorema 3.29, é consistente para e converge para .
Teorema 3.32.
Suponha que existe tal que , existe tal que , e e são invariantes a permutações (Definição 3.23). Se as condições do Teorema 3.26 ou do Teorema 3.29 estão satisfeitas, então
Exemplo 3.33 (Estimador duplamente robusto).
Considere que o grafo causal e
o modelo de geração dos dados são iguais
àqueles descritos no Exemplo 3.27.
Para implementar o estimador duplamente robusto
combinaremos o estimador da fórmula do ajuste obtido
por regressão linear no Exemplo 3.27 e
aquele de IPW por regressão logística
no Exemplo 3.30.
\MakeFramed
mu_1_lm <- data %>%
dplyr::mutate(X = 1) %>%
predict(mu_chapeu_lm, newdata = .)
mu_0_lm <- data %>%
dplyr::mutate(X = 0) %>%
predict(mu_chapeu_lm, newdata = .)
corr <- data %>%
mutate(mu_1 = mu_1_lm,
mu_0 = mu_0_lm,
f_1 = f_1_lm,
corr_1 = (X == 1)*mu_1/f_1,
corr_0 = (X == 0)*mu_0/(1-f_1)) %>%
summarise(corr_1 = mean(corr_1),
corr_0 = mean(corr_0)) %>%
mutate(corr = corr_1 - corr_0) %>%
dplyr::select(corr) %>%
as.numeric()
ace_rob_lm <- ace_ajuste_lm + ace_ipw_lm - corr
ace_rob_lm %>% round(2)
## [1] 2
5.3 Exercícios
Exercício 3.34.
Prove o Lema 3.16.
Exercício 3.35.
Prove o Lema 3.17.
Exercício 3.36.
Prove que se , então .
Exercício 3.37.
Prove que a variância amostral satisfaz o Definição 3.23.
Exercício 3.38.
Utilizando como referência o grafo e o código no Exemplo 3.27, simule dados tais que a estimativa do é diferente quando um método de regressão linear e um de regressão não-paramétrica são usados.
5.4 Regression Discontinuity Design (RDD)
Em determinadas situações, é completamente determinado pelos confundidores, (Lee2010). Por exemplo, considere que desejamos determinar o efeito causal que um determinado programa social do governo traz sobre o nível de educação dos cidadãos. Neste caso, é a indicadora de que o indíviduo é elegível ao programa e mede o seu nível de educação. Em alguns casos, é razoável supor que é completamente determinado por , a renda do indivíduo.
A situação acima traz desafios para a fórmula do ajuste e IPW discutidos anteriormente. Primeiramente, como , não é possível estimar quando . Portanto, não é possível utilizar a fórmula do ajuste, uma vez que ela se baseia na expressão . Similarmente, o estimador de IPW envolve uma divisão por . Assim, quando há uma divisão por , o que torna o estimador indefinido.
5.4.1 Identificação causal no RDD
Apesar destas dificuldades, é possível medir nestas situações parte do efeito causal de em . Suponha que e que existe tal que . Por exemplo, um benefício pode estar disponível apenas para cidadãos que tenham renda abaixo de um teto ou uma lei pode ter efeitos a partir de uma determinada data.
Neste caso, podemos estar interessados em , o efeito causal que tem na fronteira de sua implementação. Intuitivamente, próximo a esta fronteira, as unidades amostrais são todas similares em relação aos confundidores. Assim, se na fronteira houver uma diferença em entre os valores de , esta diferença deve ser decorrente do efeito causal de . Esta intuição é formalizada no resultado de identicação causal abaixo:
Teorema 3.39 (Hahn2001).
Considere que satisfaz a Definição 3.18, , e e são contínuas em .
Se , então
Se é contínua exceto em , então
Um detalhe sutil do Teorema 3.39 é que não é o suficiente para termos certeza que satisfaz o critério backdoor. Por exemplo, considere que o governo criasse um benefício fiscal para todas empresas sediadas em um determinado município. Neste caso, a ocorrência do benefício é função da sede da empresa. Contudo, a relação causal é mais complexa. Se o benefício for suficientemente alto, poderia motivar empresas a moverem sua sede para o município. Em outras palavras, o benefício seria causa da localização da sede e não o contrário. Neste caso, não seria possível aplicar o Teorema 3.39. Este tipo de raciocínio indica que a análise por RDD é mais efetiva quando é difícil interferir sobre o valor de . Por exemplo, como um indivíduo não pode interferir sobre a sua idade, é mais fácil justificar o uso de RDD em uma campanha de vacinação em que apenas indivíduos acima de uma determinada idade são vacinados.
Um outro ponto importante de interpretação do Teorema 3.39 é que, embora e sejam supostas contínuas, e não o são. Intuitivamente, podemos imaginar representa a indicadora de que uma determinada política é adotada. Por exemplo, podemos imaginar que indica que um indivíduo foi vacinado, a sua idade e a sua hospitalização. Neste caso, e representam a taxa de hospitalização quando todos os indivíduos são vacinados ou quando todos eles não o são. Nestas situações, seria razoável supor que a taxa de hospitalização é contínua em função da idade, pois não esperamos que exista uma grande descontinuidade nas condições de saúde entre indivíduos com e com anos de idade. Este tipo de conclusão muitas vezes é resumido pela expressão em latim natura non facit saltus (a natureza não faz saltos). Por outro lado, nos dados observados, a política não é adotada para uma faixa de valores de e passa a ser adotada a partir de um ponto, o que é responsável pela descontinuidade em e em . Podemos imaginar que a vacinação é empregada somente em indivíduos com mais de anos. Esta descontinuidade na política humana cria uma diferença importante entre indivíduos com e com anos, o que explica uma diferença grande nas taxas de hospitalização entre estas idades nos dados observados.
5.4.2 Estimação no RDD
O Teorema 3.39 indica que é função da regressão de sobre , , e sobre o classificador, . Uma possível estratégia é estimarmos estas quantidades separadamente e, a seguir, estimarmos o trocando as quantias populacionais pelas quantias estimadas.
Uma dificuldade nesta estratégia é que sabemos que e são discontínuas. Para lidar com esta dificuldade, uma possibilidade é realizar uma regressão para e outra para .
Definição 3.40.
Seja o conjunto de unidades amostrais em que , e regressões ajustadas utilizando apenas dados em e e ajustadas em . O estimador RDD para é
Em particular, se sabemos a priori que para e para , então
O exemplo a seguir ilustra a implementação de RDD quando utilizando tanto regressão linear quanto regressão de Kernel de Nadaraya-Watson.
Exemplo 3.41.
Considere que satisfaz o critério backdoor para estimar o efeito causal de em . Além disso, , e . Podemos simular os dados da seguinte forma:
n <- 1000 Z <- rnorm(n) X <- Z >= 0 Y <- rnorm(n, 50*(X+1)*(Z+1)) data <- tibble(X, Y, Z) plot(Z, Y)
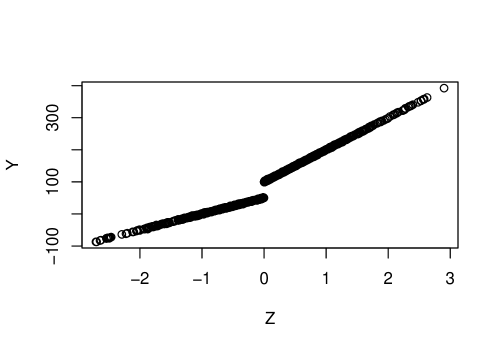
Como estamos simulando os dados, podemos calcular :
O código abaixo estima usando regressão linear:
regs = data %>% mutate(Z1 = (Z >= 0)) %>% group˙by(Z1) %>% summarise( intercepto = lm(Y ~ Z)$coefficients[1], coef_angular = lm(Y ~ Z)$coefficients[2] ) regs
## # A tibble: 2 x 3 ## Z1 intercepto coef_angular ## <lgl> <dbl> <dbl> ## 1 FALSE 50.1 50.1 ## 2 TRUE 99.9 100.
est_cace = 1*regs[2, 2] + 0*regs[2, 3] - 1*regs[1, 2] + 0*regs[1, 3] round(as.numeric(est_cace), 2)
## [1] 49.81
Similarmente, podemos estimar usando regressão por kernel de Nadaraya-Watson:
library(np) options(np.messages = FALSE) nw_reg <- function(data, valor) { bw <- npregbw(xdat = data$Z, ydat = data$Y)$bw npksum(txdat= data$Z, exdat = valor, tydat = data$Y, bws = bw)$ksum/ npksum(txdat = data$Z, exdat = valor, bws = bw)$ksum } reg_baixo <- data %>% filter(Z < 0) %>% nw˙reg(0) reg_cima <- data %>% filter(Z >= 0) %>% nw˙reg(0) est_cace <- reg_cima - reg_baixo round(est_cace, 2)
## [1] 51.31
5.5 Exercícios
Exercício 3.42.
Crie um exemplo em que, ao contrário do Exemplo 3.41, não é linear em . Compare as estimativas de usando a regressão linear e algum método de regressão não-paramétrica.