4 O modelo de probabilidade para intervenções
Com base no modelo estrutural causal discutido no capítulo 2, agora estabeleceremos um significado para o efeito causal de uma variável em outra.
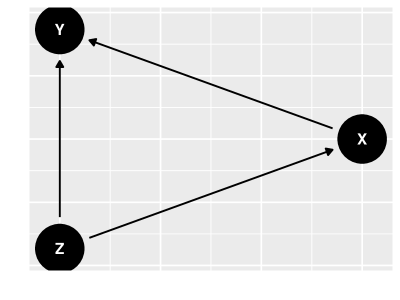
Para iniciar esta discussão, considere as variáveis (Sexo), (Tratamento), e (Cura), discutidas no capítulo 1. Podemos considerar que é uma causa tanto de quanto de e que é uma causa de . Assim, podemos representar as relações causais entre estas variáveis por meio do grafo na figur 7. Usando este grafo, podemos discutir mais a fundo porque a probabilidade condicional de cura dado tratamento é distinta do efeito causal do tratamento na cura.
Quando calculamos a probabilidade condicional de cura dado o tratamento, estamos perguntando: “Qual é a probabilidade de que um indivíduo selecionado aleatoriamente da população se cure dado que aprendemos que recebeu o tratamento?” Para responder a esta pergunta, propagamos a informação do tratamento usado em todos os caminhos do tratamento para a cura. Assim, além do efeito direto que o tratamento tem na cura, o tratamento também está associado ao sexo do paciente, o que indiretamente traz mais informação sobre a cura deste. Isto é, neste caso o tratamento traz informação tanto sobre seus efeitos (cura), quanto sobre suas causas (sexo). Uma outra maneira de verificar estas afirmações é calculando diretamente :
| (2) |
Notamos na Seção 4 que é a média das probabilidades de cura em cada sexo, , ponderadas pela distribuição do sexo após aprender o tratamento do indivíduo, .
A probabilidade condicional de cura dado tratamento não corresponde àquilo que entendemos por efeito causal de tratamento em cura. Este efeito é a resposta para a pergunta: “Qual a probabilidade de que um indivíduo selecionado aleatoriamente da população se cure dado que prescrevemos a ele o tratamento?”. Ao contrário da primeira pergunta, em que apenas observamos a população, nesta segunda fazemos uma intervenção sobre o comportamento do indivíduo. Assim, estamos fazendo uma pergunta sobre uma distribuição de probabilidade diferente, em que estamos agindo sobre a unidade amostral. Por exemplo, suponha que prescreveríamos o tratamento a qualquer indivíduo que fosse amostrado. Neste caso, saber qual tratamento foi aplicado não traria qualquer informação sobre o sexo do indivíduo. Em outras palavras, se chamarmos como a probabilidade de cura dado que fazemos uma intervenção no tratamento, faria sentido obtermos:
| (3) |
Na likning 3 temos que o efeito causal do tratamento na cura é a média ponderada das probabilidades de cura em cada sexo ponderada pelas probabilidades de sexo de um indivíduo retirado aleatoriamente da população. Isto é, ao contrário da Seção 4, a distribuição do sexo do indivíduo não é alterada quando fazemos uma intervenção sobre o tratamento.
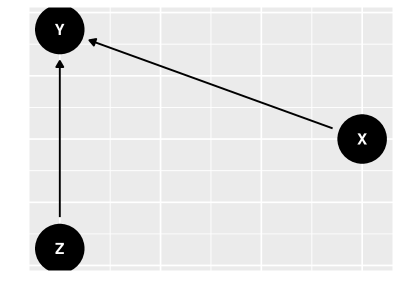
Com base neste exemplo, podemos generalizar o que entendemos por intervenção. Quando fazemos uma intervenção em uma variável, , tomamos uma ação para que assuma um determinado valor. Assim, as demais variáveis que comumente seriam causas de deixam de sê-lo. Por exemplo, para o caso na figur 7, o modelo de intervenção removeria a aresta de Sexo para Tratamento, resultado na figur 8.
Com base nas observações acima, finalmente podemos definir o modelo de probabilidade sob intervenção:
Definição 3.1.
Seja um DAG, um CM (Definição 2.24), e . O modelo de probabilidade obtido após uma intervenção em é dado por:
| , ou equivalentemente | ||||
Para compreender a Definição 3.1, podemos comparar o modelo de intervenção com o modelo observacional:
No modelo observacional, a densidade de dado é proporcional ao produto, para todos os vértices, da densidade do vértice dadas suas causas. Ao contrário, no modelo de intervenção supomos que os vértices em são pré-fixados e, assim, não são gerados por suas causas usuais. Assim, na Definição 3.1, a densidade de dada uma intervenção em é dada o produto somente nos vértices de das densidades do vértice dadas suas causas.
Esta análise é formalizada no Lema 3.2:
Lema 3.2.
Seja o grafo obtido retirando-se de todas as arestas que apontam para algum vértice em . A densidade é compatível com . Além disso, é degenerada em segundo .
Com base na discussão acima, podemos definir o efeito causal que um conjunto de variáveis, , tem em outro conjunto, :
Definição 3.3.
.
Definição 3.4.
O efeito causal médio, ACEX,Y,11 1 A sigla ACE tem como origem a expressão em inglês, Average Causal Effect. Optamos por manter a sigla sem tradução para facilitar a comparação com artigos da área. Em outros contextos, este termo também é chamado de Average Treatment Effect e recebe o acrônimo ATE. de em é dado por:
Quando não há ambiguidade, escrevemos simplesmente ao invés de .
Com a Definição 3.4 podemos finalmente desvendar o Paradoxo de Simpson discutido no capítulo 1. Veremos que o método que desenvolvemos resolve a questão com simplicidade, assim trazendo clareza ao Paradoxo.
Exemplo 3.5.
Considere que são tais que e são as indicadores de que, respectivamente, o paciente recebeu o tratamento e se curou. Além disso, suponha que a distribuição conjunta de é dada pelas frequências na tabela 1. Isto é:
Agora, veremos que a probabilidade de dada uma intervenção em depende do DAG usado no modelo causal estrutural.
Suponha que é a indicadora de que o sexo do paciente é masculino. Neste caso, utilizaremos como grafo causal aquele em figur 7. este grafo, obtemos:
| (4) |
Assim,
Portanto, o efeito causal do tratamento na cura quando é o sexo do paciente é obtido abaixo:
Como esperado da discussão na Seção 1, o tratamento tem efeito causal médio positivo, isto é, ele aumenta a probabilidade de cura do paciente.
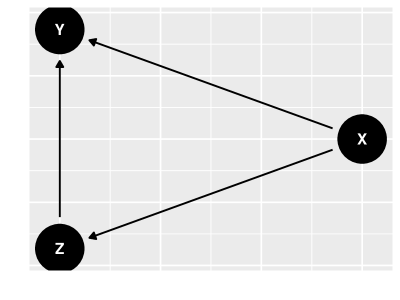
A seguir, consideramos que é a indicadora de pressão sanguínea elevada do paciente. Assim, tomamos o grafo causal como aquele na figur 9. Utilizando este grafo, obtemos:
| (5) |
Assim,
Portanto, o efeito causal do tratamento na cura quando é a pressão sanguínea do paciente é obtido abaixo:
Como esperado da discussão na Seção 1, o tratamento tem efeito causal médio negativo, isto é, ele tem como efeito colateral grave a elevação da pressão sanguínea do paciente, reduzindo a probabilidade de cura deste.
Comparando as expressões obtidas em e , verificamos que o grafo causal desempenha papel fundamental na determinação do modelo de probabilidade sob intervenção. Ademais, o uso do grafo causal adequado em cada situação formaliza a discussão qualitativa desenvolvida na Seção 1. Não há paradoxo!
Se é um CM linear Gaussiano, então é possível obter uma equação direta para o . Este resultado é apresentado no Teorema 3.6 abaixo.
Teorema 3.6.
Se é um CM linear Gaussiano de parâmetros e e é o conjunto de todos os caminhos direcionados de a , então
O Teorema 3.6 indica um algoritmo para calcular o em um CM linear Gaussiano. Primeiramente, para cada caminho direcionado de em calcula-se o produto dos coeficientes de regressão ligados a este caminho. Se imaginarmos os vértices no meio do caminho como mediadores, então estamos combinando o efeito de em , de em …e de em para obter o efeito total de em por este caminho. Ao final, somamos os efeitos totais obtidos por todos os caminhos. Cada caminho direcionado indica uma forma em que pode ter efeito sobre . Ao levarmos todoas as formas em consideração, obtemos o efeito causal médio.
Além do efeito causal médio, às vezes desejamos determinar o efeito causal de em quando observamos que a unidade amostral faz parte de determinado estrato da população. Em outras palavras, desejamos saber o efeito causal de em quando observamos que outras variáveis, , assumem um determinado valor.
Definição 3.7.
O efeito causal médio condicional, CACE, de em dado é:
Uma vez estabelecido o modelo de probabilidade utilizado quando estudamos intervenções, agora podemos fazer inferência sobre o efeito causal. Para realizar tal inferência, em geral teremos de abordar duas questões:
-
1.
Identificação causal: Temos acesso a dados que são gerados segundo a distribuição observacional. Como é possível determinar o efeito causal em termos da distribuição observacional?
-
2.
Estimação: Uma vez estabelecida uma ligação entre a distribuição observacional dos dados e o efeito causal, como é possível estimá-lo?
Nas próximas seções estudaremos algumas estratégias gerais para a resolução destas questões. Consideraremos que desejamos medir o efeito causal de em , onde .
4.1 Exercícios
Exercício 3.8.
Considere que e são variáveis binárias. Também considere as seguintes definições: ACE := , e RD := . Explique em palavras a diferença entre ACE e RD e apresente um exemplo em que essa diferença ocorre.
Exercício 3.9 (Glymour2016[p.32]).
são variáveis binárias tais que é a única causa imediata de . Além disso, , e . Calcule:
-
(a)
,
-
(b)
, ,
-
(c)
, , e
-
(d)
Exercício 3.10 (Glymour2016[p.29]).
Considere que são independentes e tais que . Também, , , e . Considere que é a causa imediata de , que por sua vez é a causa imediata de . Além disso, cada influencia diretamente somente .
-
(a)
Desenhe o DAG que representa a estrutura causal indicada no enunciado.
-
(b)
Calcule e .
-
(c)
Calcule e .
-
(d)
Calcule e .
-
(e)
Calcule , , e .