14 Uma única teoria para discretas e contínuas
14.1 Função de distribuição cumulativa
Uma maneira de especificar uma distribuição de probabilidade em é dizer o quanto de probabilidade está à esquerda de cada ponto . Em termos de uma variável aleatória com a distribuição dada, essa probabilidade é uma função de .
Definição 14.1.
Seja uma variável aleatória. A função de distribuição cumulativa de é a função definida por
para todo .
Outras probabilidades a partir de
Agora, observamos que, embora seja definido como , é possível usar para obter outras probabilidades envolvendo . Fórmulas importantes são
e, para ,
Observe também que
e, nesse caso, o tamanho do salto é a probabilidade de .
determina
Proposição 14.2.
Se e são duas variáveis aleatórias com , então e têm a mesma distribuição.
Essa proposição nos diz que a função de distribuição cumulativa realmente codifica a distribuição de uma variável aleatória (no sentido de que, dada a função de distribuição cumulativa, há apenas uma distribuição correspondente a ela).
Já vimos que determina para cada e para todo .
Faltam-nos as ferramentas necessárias para provar que ela determina para todo .
14.2 Casos discretos e contínuos
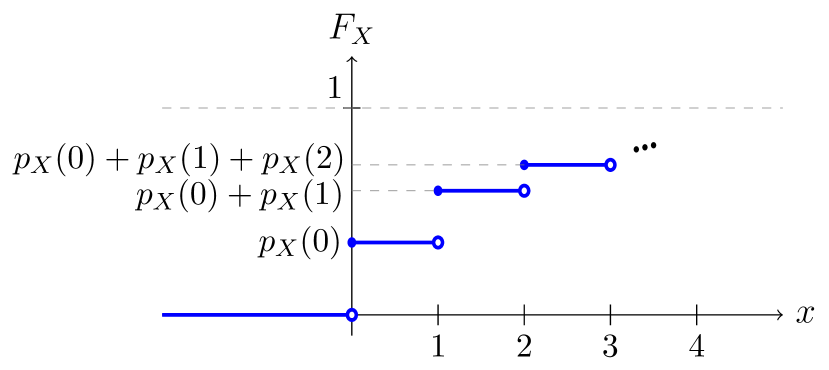
Para obter uma primeira ideia de como se parece uma função de distribuição cumulativa, consideremos o caso em que é discreto e tem suporte discreto contido em , de modo que
Em seguida, observe primeiro que para todos os . A seguir, e para todo ,
Ao argumentar de maneira semelhante, concluímos que
O gráfico de se parece com o da Figura 14.1.
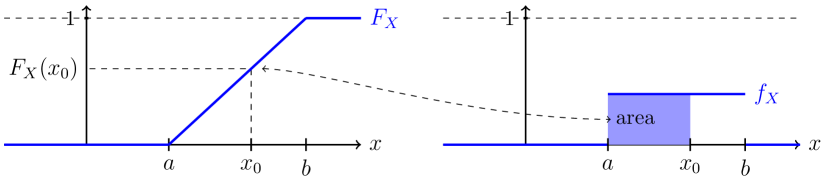
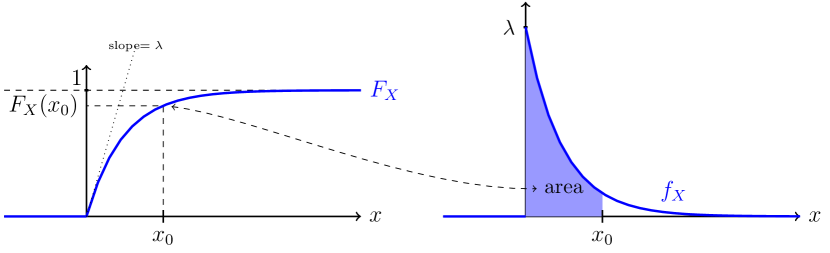
14.3 Esperança e variância
É possível fornecer uma definição unificada de esperança de uma variável aleatória, sem assumir que ela seja discreta ou que tenha uma densidade. Há uma fórmula mágica usando que funciona simultaneamente para qualquer tipo de variável aleatória. Não vamos nos preocupar em fornecer tal fórmula, mas é importante ter em mente que a esperança é algo que pode ser definido para qualquer variável aleatória limitada (e, desde que algumas somas ou integrais sejam convergentes, também pode ser definida para variáveis aleatórias ilimitadas). Novamente, dizemos que é integrável se for definido e finito.
Essa definição geral de esperança ainda satisfaz as três propriedades:
-
•
Unitária: ,
-
•
Monótona: Se para todo , então ,
-
•
Linear:
desde que e sejam integráveis.
Não provaremos essas propriedades. Claro, não poderíamos possivelmente prová-las, pois nem mesmo fornecemos a definição geral de esperança. Mas mesmo que tivéssemos escrito a fórmula, com as ferramentas atuais não seríamos capazes de provar que a esperança é linear em geral. A ideia da prova é a seguinte: quaisquer variáveis aleatórias e podem ser aproximadas por variáveis aleatórias discretas e e, uma vez que , concluímos que .
Mais uma vez, e é quadraticamente integrável se for finito, e observe que se é quadraticamente integrável, então ele é automaticamente integrável (porque ).
Definição 14.3 (Variância).
A variância de uma variável aleatória quadraticamente integrável é definida como
Observamos que a desigualdade de Chebyshev é válida para qualquer variável aleatória quadraticamente integrável. De fato, na prova dada na Seção 10.2, usamos apenas as propriedades de esperança mencionadas acima e nada mais.
Definição 14.4 (Covariância).
Também definimos a covariância de duas variáveis aleatórias quadraticamente integráveis como
e dizemos que elas são não correlacionadas se sua covariância for zero.
Observe que a covariância possui todas as propriedades mencionadas na Seção 9.2. De fato, a prova dessas propriedades usou apenas as três propriedades de esperança mencionadas acima e nada mais. Em particular, o Corolário 9.23 vale em geral, ou seja,
desde que sejam não correlacionados.
A independência é discutida na próxima seção.